


En Syloper, elegimos Git como nuestra herramienta de versionado de código. Creemos que es una herramienta fundamental, y su uso es obligatorio sin importar cuánta gente conforme el equipo de trabajo para un proyecto en particular.
Al igual que con cualquier otra herramienta, es necesario entender cómo funciona para poder hacer el mejor uso posible de ella. El objetivo de esta publicación entonces es entender qué es y cómo funciona Git.
La principal diferencia entre este recurso y cualquier otro SVC (Subversion y compañía incluidos) es cómo modela sus datos. Conceptualmente, la mayoría de los demás sistemas almacenan la información como una lista de cambios en los archivos. Estos sistemas (Subversion, Perforce, Bazaar, etc.) modelan la información que almacenan como un conjunto de archivos y las modificaciones hechas sobre cada uno de ellos a lo largo del tiempo.
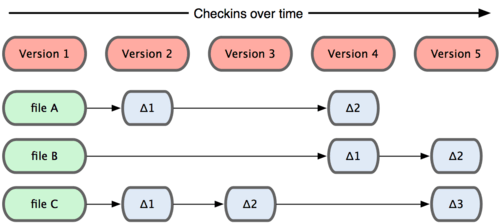
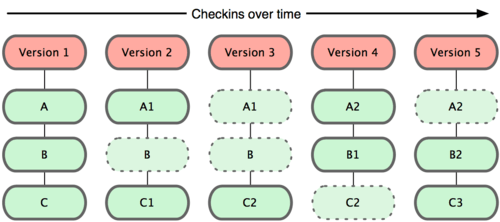
Git no modela ni almacena sus datos de este modo. En cambio, trata sus datos más como un conjunto de instantáneas de un mini sistema de archivos. Cada vez que confirmas un cambio, o guardas el estado de tu proyecto, básicamente hace una foto del aspecto de todos tus archivos en ese momento, y guarda una referencia a esa instantánea. Para ser eficiente, si los archivos no se han modificado, Git no almacena el archivo de nuevo, sólo un enlace al archivo anterior idéntico que ya tiene almacenado.
Algunas ventajas de Git
Te contamos cuáles son, en nuestra opinión, sus principales ventajas:
- Casi cualquier operación es local. La mayoría de las operaciones en esta herramienta sólo necesitan archivos y recursos locales para operar. Por lo general no se necesita información de ningún otro equipo de tu red.
- Tiene integridad. Todo en Git es verificado mediante una suma de comprobación (checksum en inglés) antes de ser almacenado, y es identificado a partir de ese momento mediante dicha suma. Esto significa que es imposible cambiar los contenidos de cualquier archivo o directorio sin que lo sepa. Esta funcionalidad está integrada al más bajo nivel y es parte integral de su filosofía. No se puede perder información durante su transmisión o sufrir corrupción de archivos sin que Git lo detecte.
- Generalmente sólo añade información. Cuando realizas acciones, casi todas ellas sólo añaden información a la base de datos de Git. Es muy difícil conseguir que el sistema haga algo que no se pueda deshacer, o que de algún modo borre información. Como en cualquier SVC, podés perder o estropear cambios que no has confirmado todavía. Pero después de confirmar una instantánea en Git, es muy difícil de perder, especialmente si envías (push) tu base de datos a otro repositorio con regularidad.
Operaciones básicas en Git
Las operaciones fundamentales de esta herramienta son pocas, y pueden comprenderse observando el siguiente diagrama, que muestra el proceso de almacenar cambios en nuestro repositorio local.
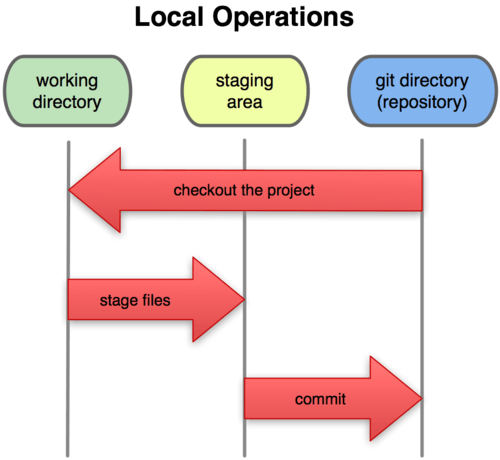
- Checkout: es la acción de clonar el proyecto en nuestro equipo para comenzar a trabajar, bastará con correr en consola el comando git clone url_de_proyecto nombre_de_carpeta. La URL del proyecto es la del repositorio que hayamos creado por ejemplo en Gitlab, Github, etcétera. El nombre de la carpeta que contendrá al proyecto es opcional, pero suele ser una buena práctica incluirlo.
- Stage: es el proceso de «preparar» nuestros archivos modificados para su posterior commit. Una vez que hayamos creado o modificado los archivos que queramos, bastará con enviarlos al staging area utilizando el comando git add ruta_de_archivo.
- Commit: finalmente, para persistir los cambios en nuestro repositorio local de Git y poder enviarlos al repositorio global (para actualizar el entorno de producción de un proyecto por ejemplo), es necesario hacer un commit o confirmación de nuestros cambios. Para ello, bastará con correr el comando git commit -m ‘Mensaje descriptivo de los cambios que introduce el commit’.
Es imperativo que el commit tenga un mensaje descriptivo, ya que de esa forma facilitamos el trabajo al resto del equipo, y ante el eventual fallo de nuestra aplicación, el historial de git es un buen lugar para empezar a buscar dónde se pudo haber introducido el bug.
Finalmente, y para no hacer más extenso este post, ¡nos despedimos hasta la próxima ocasión, y esperamos que lo hayan disfrutado!
Somos Syloper, una empresa de desarrollo de software con base en Rosario, Argentina y con proyección hacia toda Latinoamérica.
▶ Si te interesa lo que hacemos y necesitás nuestra ayuda, escribinos.